|
|
一、项目介绍
在消费市场中,研究消费者需求对企业而言至关重要。从消费者行为、偏好等方面挖掘用户特征以及市场趋势,可以帮助企业更好提高经营效益。酒店行业,主营业务主要是提供客房住宿、餐饮、会议场所等服务,在目前的经济形势下,竞争愈发激烈。酒店经营效益可以考虑从改善收益管理、营销推广、服务完善等方面来提高。
本项目主要是依据酒店预订数据集围绕收益管理、营销推广、服务完善三个方向进行数据探讨:
1.数据集简要说明
该数据集依据两家酒店为主体,分别是一家度假酒店与一家城市酒店,这两家均位于葡萄牙(Portugal),度假酒店(Resort hotel)在阿尔加维(Algarve),城市酒店(City hotel)则位于葡萄牙首都里斯本(Lisbon),两个酒店在地理位置上跨度较大,数据之间相互干扰的影响较小。
数据集按照预订到店的时间,跨度为2015年7月1日至2017年8月31日。
2.数据来源:Kaggle网站
3.项目问题探讨
本项目的研究思路大致如下方的思维导图所示:
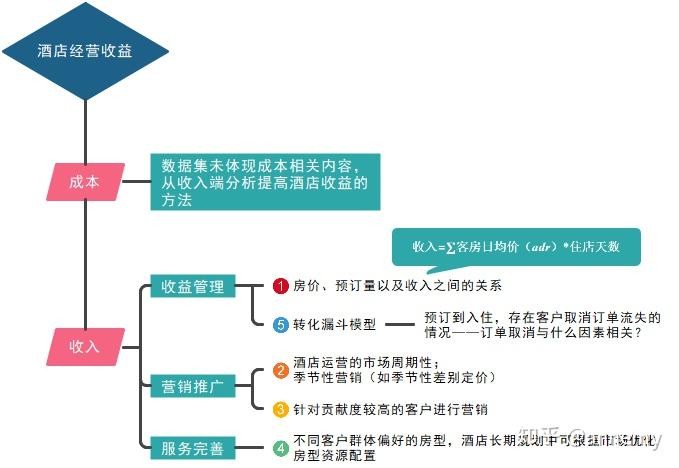
本项目流程如下:

二、具体实施
1.准备工作——获取数据
#导库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
from sklearn.model_selection import train_test_split, KFold, cross_val_score,GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import LabelEncoder,StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestClassifier
#显示设置
pd.set_option("display.max_columns", None) #设置显示全部列
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
sns.set(font='SimHei') # 解决Seaborn中文显示问题
#读取数据
file_path=r"D:\数据分析\项目\hotel_bookings\hotel_bookings.csv"
data_origin=pd.read_csv(file_path)
#数据备份
data=data_origin.copy()2.准备工作——熟悉数据
data.head()
data.shape
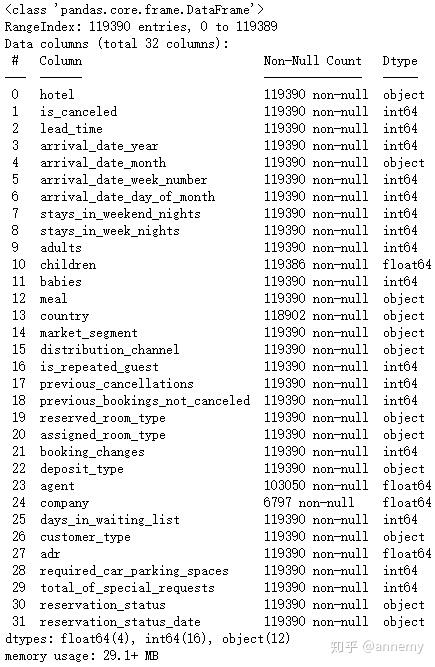
data.info()
# hotel 酒店类型
# is_canceled 预订是否取消(0,1)
# lead_time 提前预订天数
# arrival_date_year 入住年份
# arrival_date_month 入住月份
# arrival_date_week_number 入住周数
# arrival_date_day_of_month 入住日期
# stays_in_weekend_nights 周末过夜数
# stays_in_week_nights 工作日过夜数
# adults 成人人数
# children 儿童人数
# babies 婴儿人数
# meal 餐食类型(BB早餐,HB午餐,FB晚餐,Undefined/SC无餐)
# country 客户来源国家
# market_segment 市场细分
# distribution_channel 订单渠道
# is_repeated_guest 是否是老客户
# previous_cancellations 历史取消预订的次数
# previous_bookings_not_canceled 历史未取消预订的次数
# reserved_room_type 预定房间类型
# assigned_room_type 实际房间类型
# booking_changes 预定更改次数
# deposit_type 押金类型(No Deposit,Non Refund,Refundable)
# agent 预订旅行社ID
# company 预订公司/实体ID
# days_in_waiting_list 等待天数
# customer_type 客户类型
# adr 客房日均价
# required_car_parking_spaces 车位需求数
# total_of_special_requests 特殊需求数
# reservation_status 预订最终状态(Canceled,Check-out,No-show)
# reservation_status_date 预订最终状态更新日期
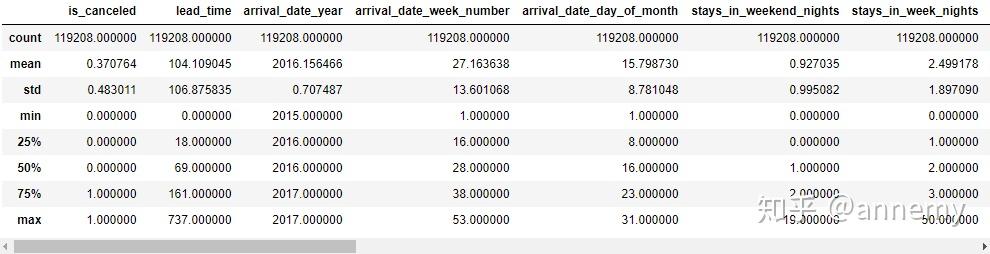
data.describe()
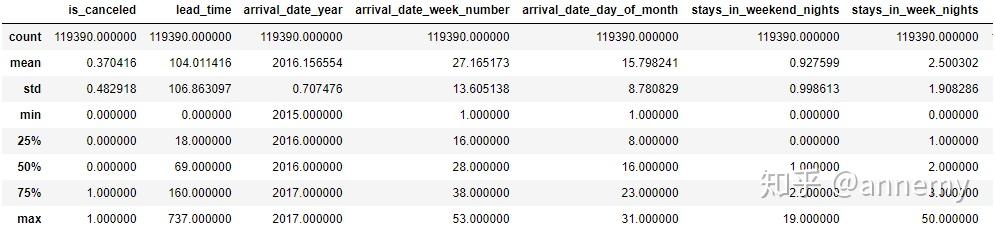
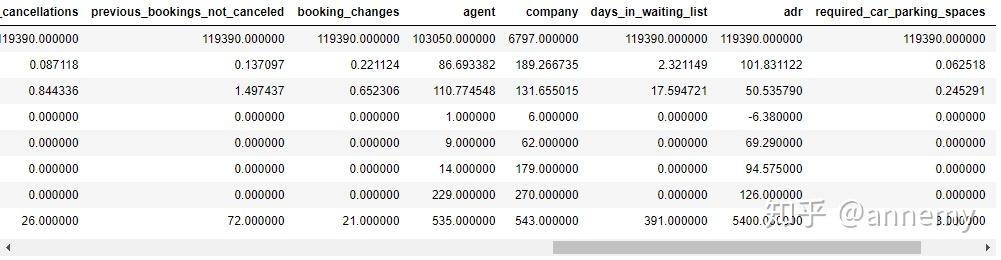
通过观察数据,发现1个异常点:客房日均价(adr)不为负,应剔除adr为负的异常值,adr最大值为5400,显然远远大于均值+3倍标准差。用箱形图看下异常值:
plt.figure(figsize=(12, 1))
sns.boxplot(x=list(data["adr"]))
plt.show()

数据清洗中,需要剔除adr明显不合理的异常值。
#查看缺失值
missing=data.isnull().sum()
missing[missing!=0]

3.数据清洗
(1)缺失值填充
① country缺失的,无法补充,缺失值用unknown进行区分 ; ② children缺失的,可理解为没有儿童入住,故订单登记中未填,缺失值用0填充; ③ agent缺失的,可理解为非旅行社预订,故订单登记中未填,缺失值用0填充; ④ company缺失的,可理解为非公司预订,故订单登记中未填,缺失值用0填充;
data_fill=data.fillna({"children":0,"agent":0,"company":0,"country":"unknow"})
missing=data_fill.isnull().sum()
missing[missing!=0]
缺失值填充完毕。
(2)异常值处理
(1)adults与children入住人数之和为0; (2)客房日均价为负,客房日均价高于1000元; (3)meal中undefined与sc均表示无餐。
drop_a=data_fill[data_fill[["adults","children"]].sum(axis=1)==0]
drop_b=data_fill[(data_fill[&#34;adr&#34;]<0) | (data_fill[&#34;adr&#34;]>1000)]
data_fill.drop(drop_a.index,inplace=True)
data_done=data_fill[(data_fill[&#34;adr&#34;]>=0) & (data_fill[&#34;adr&#34;]<1000)]
data_done[&#34;meal&#34;].replace({&#34;Undefined&#34;:&#34;SC&#34;},inplace=True)
data_done.shape
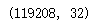
数据清洗完以后,还剩下119208条记录。
为了方便后续分析,给数据表增加income,nights两列。 nights表示入住晚数,nights=stays_in_weekend_nights+stays_in_week_nights income=adr(客房日均价)*入住晚数
data_done[&#34;income&#34;]=data_done[&#34;adr&#34;]*data_done[[&#34;stays_in_weekend_nights&#34;,&#34;stays_in_week_nights&#34;]].sum(axis=1)
data_done[&#34;nights&#34;]=data_done[[&#34;stays_in_weekend_nights&#34;,&#34;stays_in_week_nights&#34;]].sum(axis=1)
data_done.describe()
将数据分成度假酒店与城市酒店两组:
data_re = data_done[(data_done[&#34;hotel&#34;] == &#34;Resort Hotel&#34;) & (data_done[&#34;is_canceled&#34;] == 0)]
data_ci = data_done[(data_done[&#34;hotel&#34;] == &#34;City Hotel&#34;) & (data_done[&#34;is_canceled&#34;] == 0)]4.数据可视化分析
(1)房价、预订量与收入三者之间的关系
①房价、预订量的关系
data_re[&#34;group_adr&#34;]=data_re[&#34;adr&#34;]//10*10
re_group_nights=data_re.groupby(&#34;group_adr&#34;)[&#34;nights&#34;].sum()
re_group_nights_data=pd.DataFrame({&#34;group_adr&#34;: list(re_group_nights.index),
&#34;hotel&#34;: &#34;Resort hotel&#34;,
&#34;nights&#34;: list(re_group_nights.values)})
data_ci[&#34;group_adr&#34;]=data_ci[&#34;adr&#34;]//10*10
ci_group_nights=data_ci.groupby(&#34;group_adr&#34;)[&#34;nights&#34;].sum()
ci_group_nights_data=pd.DataFrame({&#34;group_adr&#34;: list(ci_group_nights.index),
&#34;hotel&#34;: &#34;City hotel&#34;,
&#34;nights&#34;: list(ci_group_nights.values)})
nights_data = pd.concat([re_group_nights_data,ci_group_nights_data], ignore_index=True)
#绘图
plt.figure(figsize=(12, 8))
ax1=sns.barplot(x = &#34;group_adr&#34;, y=&#34;nights&#34;,hue=&#34;hotel&#34;,hue_order = [&#34;City hotel&#34;, &#34;Resort hotel&#34;], data=nights_data)
plt.title(&#34;客房日均价与预订量的关系&#34;, fontsize=16)
plt.xlabel(&#34;客房日均价&#34;, fontsize=16)
plt.xticks(rotation=45)
plt.ylabel(&#34;预订量&#34;, fontsize=16)
plt.show()
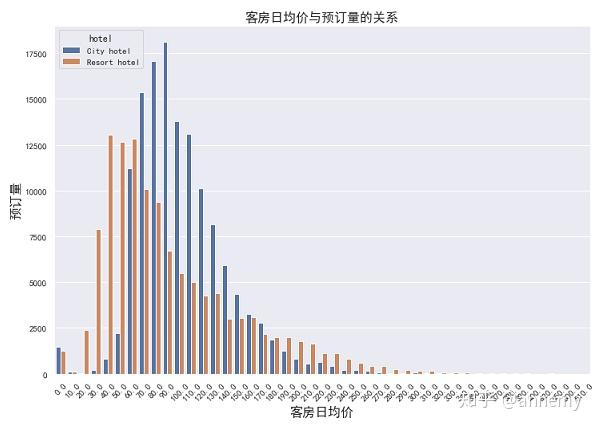
随着客房日均价的提高,预订量(nights)呈现出先增加后减少的趋势。城市酒店图形面积大于度假酒店,城市酒店的市场需求较度假酒店旺盛;
城市酒店的最高点(90元)比度假酒店(60元)晚出现,城市酒店也拥有较强的定价权,在高点右边,随着价格的提高,城市酒店预订量下降的速度比度假酒店快,说明城市酒店客户价格敏感性较高,过度提高价格可能会造成大量客户的流失。
②房价、收入的关系
re_group_income=data_re.groupby(&#34;group_adr&#34;)[&#34;income&#34;].sum()
re_group_income_data=pd.DataFrame({&#34;group_adr&#34;: list(re_group_income.index),
&#34;hotel&#34;: &#34;Resort hotel&#34;,
&#34;income&#34;: list(re_group_income.values)})
ci_group_income=data_ci.groupby(&#34;group_adr&#34;)[&#34;income&#34;].sum()
ci_group_income_data=pd.DataFrame({&#34;group_adr&#34;: list(ci_group_income.index),
&#34;hotel&#34;: &#34;City hotel&#34;,
&#34;income&#34;: list(ci_group_income.values)})
income_data = pd.concat([re_group_income_data,ci_group_income_data], ignore_index=True)
#绘图
plt.figure(figsize=(6, 6))
ax1=sns.lineplot(x = &#34;group_adr&#34;, y=&#34;nights&#34;,hue=&#34;hotel&#34;,hue_order = [&#34;City hotel&#34;, &#34;Resort hotel&#34;], data=nights_data)
plt.title(&#34;客房日均价与预订量的关系&#34;, fontsize=16)
plt.xlabel(&#34;客房日均价&#34;, fontsize=16)
plt.xticks(rotation=45)
plt.ylabel(&#34;预订量&#34;, fontsize=16)
plt.show()
plt.figure(figsize=(6, 6))
ax2=sns.lineplot(x = &#34;group_adr&#34;, y=&#34;income&#34;,hue=&#34;hotel&#34;,hue_order = [&#34;City hotel&#34;, &#34;Resort hotel&#34;], data=income_data)
plt.title(&#34;客房日均价与客房收入的关系&#34;, fontsize=16)
plt.xlabel(&#34;客房日均价&#34;, fontsize=16)
plt.xticks(rotation=45)
plt.ylabel(&#34;客房收入&#34;, fontsize=16)
plt.show()
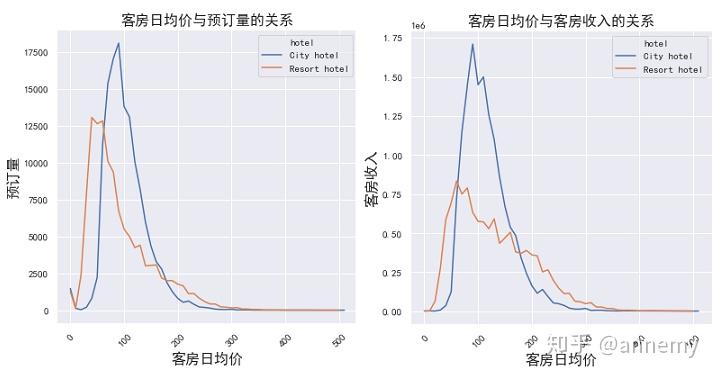
客房收入-客房日均价、预订量-客房日均价的走势大致相同,但高点右侧,随着客房日均价的提高,客房收入下降的幅度与预订量相比较为缓和,主要原因系客房日均价的提高在同等情况下可以提高客房收入,但价格的提高同时也会造成预订量的下降,并且预订量下降对收入的影响更大;
分酒店类型来分析,度假酒店上述的缓和程度比城市酒店更加明显,可能是因为度假酒店的客户更倾向于长住(毕竟是出去旅游的),度假酒店客户的价格弹性较小;对应地,城市酒店实施降价促销的方式可能比度假酒店更有效,因为对城市酒店的客房收入而言,客房日均价的敏感系数更高。
③客房日均价、预订量以及客房收入的变动趋势(周期性探讨)
# 按月份排序:
ordered_months = [&#34;January&#34;, &#34;February&#34;, &#34;March&#34;, &#34;April&#34;, &#34;May&#34;, &#34;June&#34;,
&#34;July&#34;, &#34;August&#34;, &#34;September&#34;, &#34;October&#34;, &#34;November&#34;, &#34;December&#34;]
data_mothly[&#34;arrival_date_month&#34;] = pd.Categorical(data_mothly[&#34;arrival_date_month&#34;], categories=ordered_months, ordered=True)
data_mothly[&#34;arrival_date_month&#34;].replace({&#34;January&#34;:1, &#34;February&#34;:2, &#34;March&#34;:3, &#34;April&#34;:4, &#34;May&#34;:5, &#34;June&#34;:6,
&#34;July&#34;:7, &#34;August&#34;:8, &#34;September&#34;:9, &#34;October&#34;:10, &#34;November&#34;:11, &#34;December&#34;:12},inplace=True)
re_monthly=data_mothly[data_mothly[&#34;hotel&#34;]==&#34;Resort Hotel&#34;]
ci_monthly=data_mothly[data_mothly[&#34;hotel&#34;]==&#34;City Hotel&#34;]
re_adr_monthly = round(re_monthly.groupby([&#34;arrival_date_year&#34;,&#34;arrival_date_month&#34;])[&#34;adr&#34;].mean(),2)
re_income_monthly = re_monthly.groupby([&#34;arrival_date_year&#34;,&#34;arrival_date_month&#34;])[&#34;income&#34;].sum()
re_nights_monthly = re_monthly.groupby([&#34;arrival_date_year&#34;,&#34;arrival_date_month&#34;])[&#34;nights&#34;].sum()
re_monthly_data = pd.DataFrame({&#34;month&#34;: list(re_adr_monthly.index),
&#34;hotel&#34;: &#34;Resort Hotel&#34;,
&#34;adr&#34;: list(re_adr_monthly),
&#34;income&#34;: list(re_income_monthly),
&#34;nights&#34;: list(re_nights_monthly)})
ci_adr_monthly = round(ci_monthly.groupby([&#34;arrival_date_year&#34;,&#34;arrival_date_month&#34;])[&#34;adr&#34;].mean(),2)
ci_income_monthly = ci_monthly.groupby([&#34;arrival_date_year&#34;,&#34;arrival_date_month&#34;])[&#34;income&#34;].sum()
ci_nights_monthly = ci_monthly.groupby([&#34;arrival_date_year&#34;,&#34;arrival_date_month&#34;])[&#34;nights&#34;].sum()
ci_monthly_data = pd.DataFrame({&#34;month&#34;: list(ci_adr_monthly.index),
&#34;hotel&#34;: &#34;City Hotel&#34;,
&#34;adr&#34;: list(ci_adr_monthly),
&#34;income&#34;: list(ci_income_monthly),
&#34;nights&#34;: list(ci_nights_monthly)})
monthly_data_all = pd.concat([re_monthly_data,ci_monthly_data], ignore_index=True)
plt.figure(figsize=(12, 8))
ax1=sns.catplot(x = &#34;month&#34;, y=&#34;adr&#34;, hue=&#34;hotel&#34;,data=monthly_data_all, kind=&#34;point&#34;,hue_order = [&#34;City Hotel&#34;, &#34;Resort Hotel&#34;],height=5,
aspect=2.5)
plt.title(&#34;客房日均价的走势图&#34;, fontsize=16)
plt.xlabel(&#34;时间&#34;, fontsize=16)
plt.xticks(rotation=45)
plt.ylabel(&#34;客房日均价&#34;, fontsize=16)
plt.show()
plt.figure(figsize=(12, 8))
ax2=sns.catplot(x = &#34;month&#34;, y=&#34;income&#34;, hue=&#34;hotel&#34;,data=monthly_data_all,kind=&#34;point&#34;,
hue_order = [&#34;City Hotel&#34;, &#34;Resort Hotel&#34;],height=5,
aspect=2.5)
plt.title(&#34;客房月度收入的走势图&#34;, fontsize=16)
plt.xlabel(&#34;时间&#34;, fontsize=16)
plt.xticks(rotation=45)
plt.ylabel(&#34;月度收入&#34;, fontsize=16)
plt.show()
plt.figure(figsize=(12, 8))
ax3=sns.catplot(x = &#34;month&#34;, y=&#34;nights&#34;, hue=&#34;hotel&#34;,data=monthly_data_all, kind=&#34;point&#34;,
hue_order = [&#34;City Hotel&#34;, &#34;Resort Hotel&#34;],height=5,
aspect=2.5)
plt.title(&#34;月度总预定量的走势图&#34;, fontsize=16)
plt.xlabel(&#34;时间&#34;, fontsize=16)
plt.xticks(rotation=45)
plt.ylabel(&#34;预定量&#34;, fontsize=16)
plt.show()
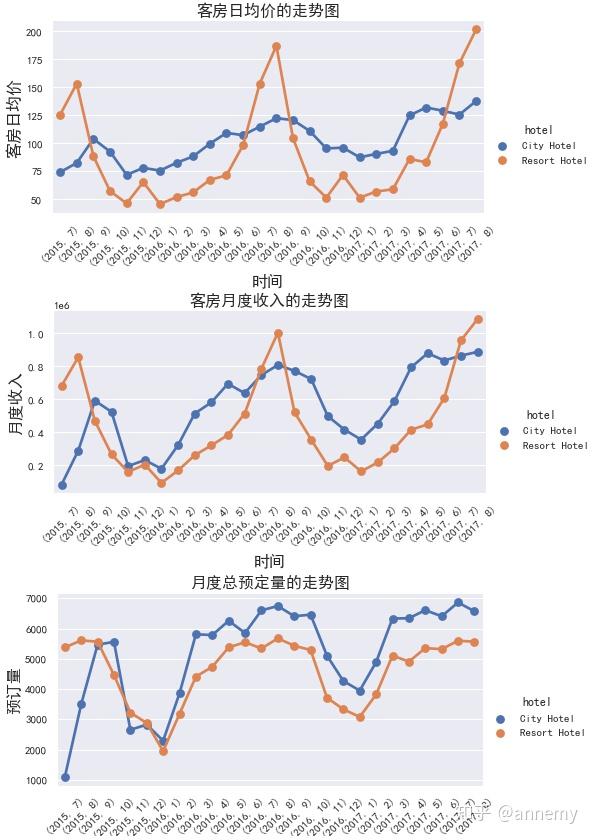
酒店的周期性较为明显,6至9月是旺季,在旺季期间,随着客流量的增加,酒店采取了提价的方式快速增加客房收入;11月至次年2月为淡季,12月的小峰值可能系国外圣诞节的影响。9-10月以及4-6月的平淡期,酒店通过降低价格,酒店预订量有所提高,但整体的收入较旺季依然是下降的。从酒店类别分析,度假酒店价格的调整幅度明显大于城市酒店,旺季时度假酒店价格高于城市酒店,淡季相反。
(3)不同地区客户收入贡献以及变动情况
#地区客户贡献度,针对性营销
data_1=data_eff[(data_eff[&#34;hotel&#34;]==&#34;Resort Hotel&#34;) & (data_eff[&#34;arrival_date_year&#34;]==2015)]
data_2=data_eff[(data_eff[&#34;hotel&#34;]==&#34;Resort Hotel&#34;) & (data_eff[&#34;arrival_date_year&#34;]==2016)]
data_3=data_eff[(data_eff[&#34;hotel&#34;]==&#34;Resort Hotel&#34;) & (data_eff[&#34;arrival_date_year&#34;]==2017)]
data_4=data_eff[(data_eff[&#34;hotel&#34;]==&#34;City Hotel&#34;) & (data_eff[&#34;arrival_date_year&#34;]==2015)]
data_5=data_eff[(data_eff[&#34;hotel&#34;]==&#34;City Hotel&#34;) & (data_eff[&#34;arrival_date_year&#34;]==2016)]
data_6=data_eff[(data_eff[&#34;hotel&#34;]==&#34;City Hotel&#34;) & (data_eff[&#34;arrival_date_year&#34;]==2017)]
ax1 = px.pie(data_1
,values=&#34;income&#34;
,names=&#34;country&#34;
,title=&#34;2015年Resort Hotel不同地区客户收入贡献率&#34;
,template=&#34;seaborn&#34;
)
ax1.update_traces(textposition=&#34;inside&#34;,textinfo=&#34;value+percent+label&#34;)
ax1.show()
ax2 = px.pie(data_2
,values=&#34;income&#34;
,names=&#34;country&#34;
,title=&#34;2016年Resort Hotel不同地区客户收入贡献率&#34;
,template=&#34;seaborn&#34;
)
ax2.update_traces(textposition=&#34;inside&#34;,textinfo=&#34;value+percent+label&#34;)
ax2.show()
ax3 = px.pie(data_3
,values=&#34;income&#34;
,names=&#34;country&#34;
,title=&#34;2017年Resort Hotel不同地区客户收入贡献率&#34;
,template=&#34;seaborn&#34;
)
ax3.update_traces(textposition=&#34;inside&#34;,textinfo=&#34;value+percent+label&#34;)
ax3.show()
ax4 = px.pie(data_4
,values=&#34;income&#34;
,names=&#34;country&#34;
,title=&#34;2015年City Hotel不同地区客户收入贡献率&#34;
,template=&#34;seaborn&#34;
)
ax4.update_traces(textposition=&#34;inside&#34;,textinfo=&#34;value+percent+label&#34;)
ax5 = px.pie(data_5
,values=&#34;income&#34;
,names=&#34;country&#34;
,title=&#34;2016年City Hotel不同地区客户收入贡献率&#34;
,template=&#34;seaborn&#34;
)
ax5.update_traces(textposition=&#34;inside&#34;,textinfo=&#34;value+percent+label&#34;)
ax5.show()
ax6 = px.pie(data_6
,values=&#34;income&#34;
,names=&#34;country&#34;
,title=&#34;2017年City Hotel不同地区客户收入贡献率&#34;
,template=&#34;seaborn&#34;
)
ax6.update_traces(textposition=&#34;inside&#34;,textinfo=&#34;value+percent+label&#34;)
ax6.show()
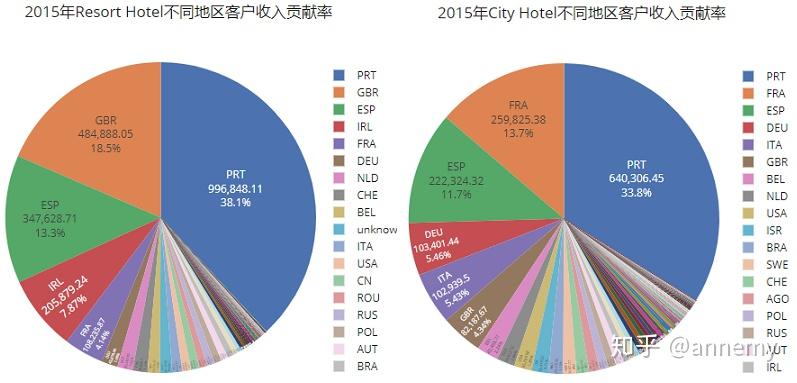
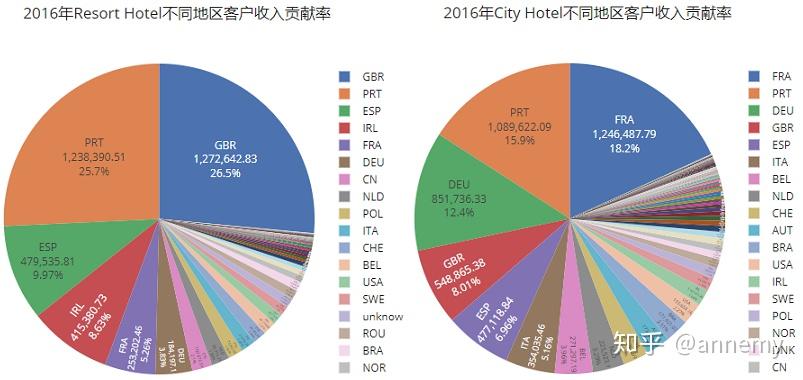
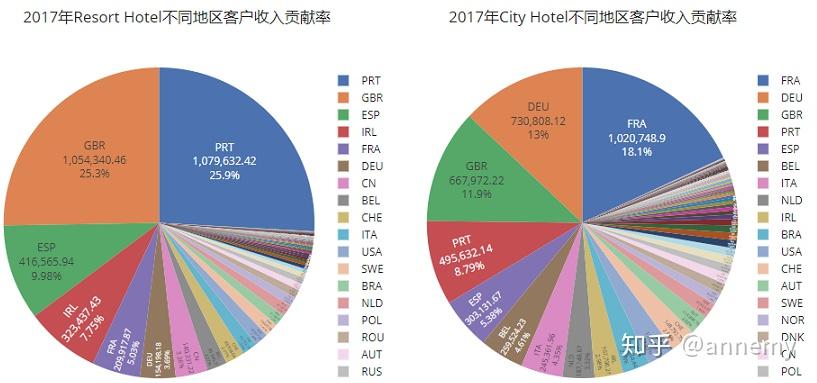
度假酒店的主要客户来源PRT(葡萄牙)、GBR(英国)、ESP(西班牙)三个国家,占比前三名的客户来源地构成较为稳定。城市酒店的排名前三的客户来源地处较为不稳定,2015年排名第三的ESP,在2016年、2017年都未进入前三,2015年排名第一的PRT(葡萄牙),2016年排名第二,2017年退出前三。度假酒店应当更注重对老顾客的维护,比如说具有较大消费潜力的PRT客户针对性推送营销。
(4)市场细分、房型偏好
group_country=data_eff.groupby(&#34;country&#34;)[&#34;income&#34;].sum()
income_total=group_country.values.sum()
group_country_data=pd.DataFrame({&#34;country&#34;:list(group_country.index)
,&#34;income&#34;:list(group_country)})
group_country_data[&#34;income %&#34;]=round(group_country_data[&#34;income&#34;]/ income_total*100,2)
group_country_data_s=group_country_data[group_country_data[&#34;income %&#34;]>10]
group_country_data_s
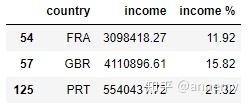
选择整体数据集来源地占比最高的三个国家(FRA法国,GBR,PRT)进行进一步分析:
data_eff_s=data_eff[data_eff[&#34;country&#34;].isin([&#34;FRA&#34;,&#34;GBR&#34;,&#34;PRT&#34;])].sort_values(by=[&#34;reserved_room_type&#34;])
plt.figure(figsize=(12, 10))
ax1=sns.catplot(x=&#34;market_segment&#34;,
y=&#34;nights&#34;,
estimator=sum,
col=&#34;country&#34;,
data=data_eff_s,
kind=&#34;bar&#34;)
ax1.set_xticklabels(rotation=45)
ax2=sns.catplot(x=&#34;market_segment&#34;,
y=&#34;adr&#34;,
col=&#34;country&#34;,
data=data_eff_s,
kind=&#34;bar&#34;)
ax2.set_xticklabels(rotation=45)
ax3=sns.catplot(x=&#34;reserved_room_type&#34;,
y=&#34;nights&#34;,
estimator=sum,
col=&#34;country&#34;,
data=data_eff_s,
kind=&#34;bar&#34;)
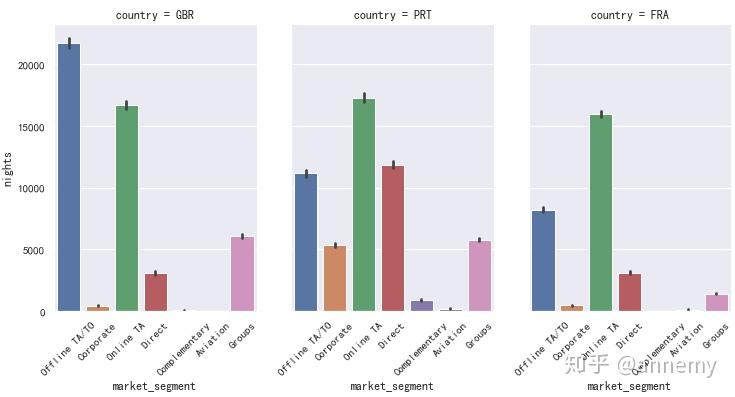
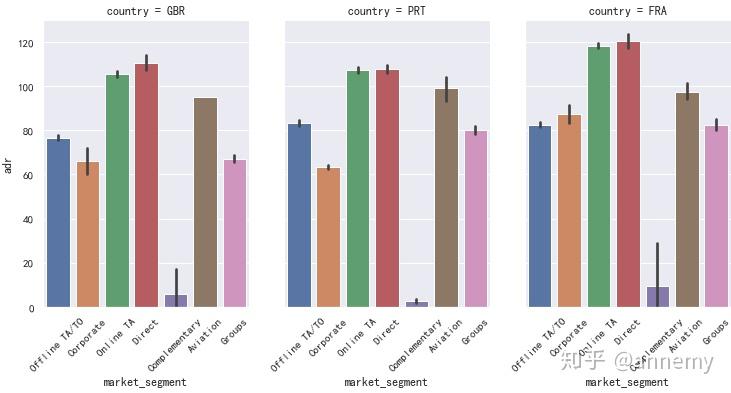
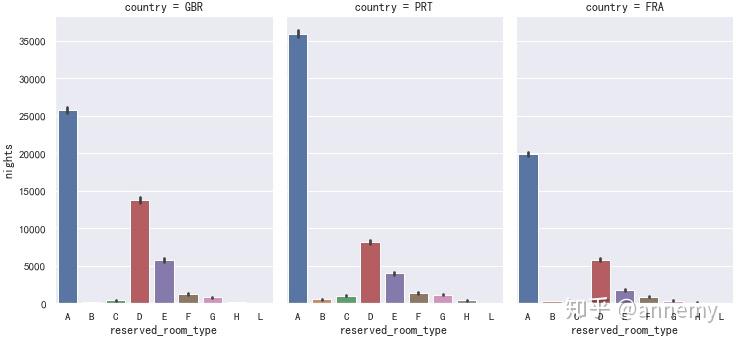
三个国家中,GBR最喜欢采用线下旅行社代理,其他两个国家的顾客更喜欢线上预订,在客房日均价上,三个国家都是公司预订以及线上预订产生的订单的客房日均价最高。房型的偏好也是三个国家之间的共性,A房型预订数量最多。
(5)转化漏斗,预定取消率影响因素分析
#建模前需要对数值型特征归一化,类别特征数值化(one-hot编码)
num_features = [&#34;lead_time&#34;,&#34;arrival_date_week_number&#34;,&#34;arrival_date_day_of_month&#34;,
&#34;stays_in_weekend_nights&#34;,&#34;stays_in_week_nights&#34;,&#34;adults&#34;,&#34;children&#34;,
&#34;babies&#34;,&#34;is_repeated_guest&#34;, &#34;previous_cancellations&#34;,
&#34;previous_bookings_not_canceled&#34;,&#34;agent&#34;,&#34;company&#34;,
&#34;required_car_parking_spaces&#34;, &#34;total_of_special_requests&#34;, &#34;adr&#34;]
num_transformer = Pipeline(steps=[
(&#39;imputer&#39;, SimpleImputer(strategy=&#39;constant&#39;)),
(&#39;scaler&#39;, StandardScaler())])
cat_features = [&#34;hotel&#34;,&#34;arrival_date_month&#34;,&#34;meal&#34;,&#34;market_segment&#34;,
&#34;distribution_channel&#34;,&#34;reserved_room_type&#34;,&#34;deposit_type&#34;,&#34;customer_type&#34;]
cat_transformer = Pipeline(steps=[
(&#34;imputer&#34;, SimpleImputer(strategy=&#34;constant&#34;, fill_value=&#34;Unknown&#34;)),
(&#34;onehot&#34;, OneHotEncoder(handle_unknown=&#39;ignore&#39;))])
features = num_features + cat_features
preprocessor = ColumnTransformer(
transformers=[
(&#39;num&#39;, num_transformer, num_features),
(&#39;cat&#39;, cat_transformer, cat_features)])
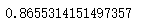
#调参
scorel = []
for i in range(0,200,10):
rfc_model = RandomForestClassifier(n_estimators=i+1,
n_jobs=-1,
random_state=0)
rfc = Pipeline(steps=[(&#39;preprocessor&#39;, preprocessor),
(&#39;model&#39;,rfc_model)])
split = KFold(n_splits=10, shuffle=True, random_state=42)
rfc_t_s = cross_val_score(rfc,
X, y,
cv=split,
scoring=&#34;accuracy&#34;,
n_jobs=-1).mean()
scorel.append(rfc_t_s)
print(max(scorel),(scorel.index(max(scorel))*10)+1)
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scorel)
plt.show()
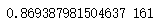
scorel = []
for i in range(150,170):
rfc_model = RandomForestClassifier(n_estimators=i,
n_jobs=-1,
random_state=0)
rfc = Pipeline(steps=[(&#39;preprocessor&#39;, preprocessor),
(&#39;model&#39;,rfc_model)])
split = KFold(n_splits=10, shuffle=True, random_state=42)
rfc_t_s = cross_val_score(rfc,
X, y,
cv=split,
scoring=&#34;accuracy&#34;,
n_jobs=-1).mean()
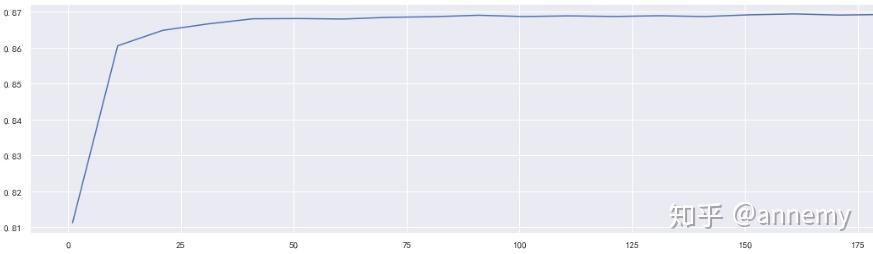
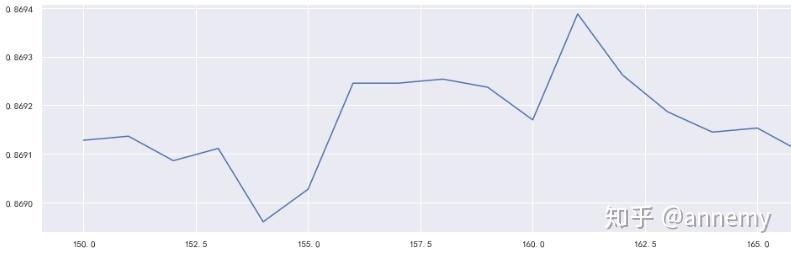
scorel.append(rfc_t_s)
print(max(scorel),([*range(150,170)][scorel.index(max(scorel))]))
plt.figure(figsize=[20,5])
plt.plot(range(150,170),scorel)
plt.show()
param_grid = {
&#34;model__max_depth&#34;:[*range(1,40,10)]
,&#39;model__min_samples_leaf&#39;:[*range(1,50,10)]
}
rfc_model_t = RandomForestClassifier(n_estimators=161,
criterion=&#34;gini&#34;,
max_features=0.4,
n_jobs=-1,
random_state=0)
rfc_t = Pipeline(steps=[(&#39;preprocessor&#39;, preprocessor),
(&#39;model&#39;,rfc_model_t)])
split_t = KFold(n_splits=10, shuffle=True, random_state=42)
X = data_done.drop(&#34;is_canceled&#34;,axis=1)
y = data_done[&#34;is_canceled&#34;]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
GS = GridSearchCV(rfc_t, param_grid, cv=split_t)# 同时满足 fit score 和交叉验证三种功能
GS.fit(X_train, y_train)
GS.best_params_
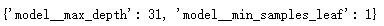
#训练模型,评估模型
rfc_model = RandomForestClassifier(n_estimators=161
,criterion=&#34;gini&#34;
,max_depth=31
,min_samples_leaf=1
,max_features=0.4
,n_jobs=-1
,random_state=0)
rfc = Pipeline(steps=[(&#39;preprocessor&#39;, preprocessor),
(&#39;model&#39;,rfc_model)])
rfc=rfc.fit(X_train, y_train)
score_=rfc.score(X_test, y_test)
score_
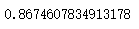
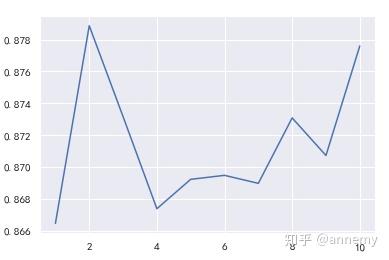
#交叉检验
split = KFold(n_splits=10, shuffle=True, random_state=42)
rfc_s = cross_val_score(rfc,
X, y,
cv=split,
scoring=&#34;accuracy&#34;,
n_jobs=-1)
plt.plot(range(1,11),rfc_s,label = &#34;RandomForest&#34;)
#特征重要性
import eli5
onehot_columns = list(rfc.named_steps[&#39;preprocessor&#39;].
named_transformers_[&#39;cat&#39;].
named_steps[&#39;onehot&#39;].
get_feature_names(input_features=cat_features))
feat_imp_list = num_features + onehot_columns
#按重要排序的前10个重要特征及其系数
feat_imp_df = eli5.formatters.as_dataframe.explain_weights_df(
rfc.named_steps[&#39;model&#39;],
feature_names=feat_imp_list)
feat_imp_df.head(10)
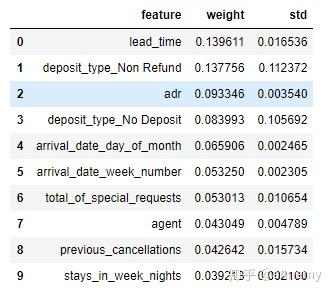
对权重大于10%的影响因素(提前预订时间以及保证金类型)进行进一步分析:
#预定取消与提前预定时间的关系
lead_cancel_data = data_done.groupby(&#34;lead_time&#34;)[&#34;is_canceled&#34;].describe()
plt.figure(figsize=(12, 8))
# sns.catplot(x=lead_cancel_data.index, y=lead_cancel_data[&#34;mean&#34;].values * 100,color=&#39;olive&#39;)
sns.scatterplot(x=lead_cancel_data.index, y=lead_cancel_data[&#34;mean&#34;].values * 100,color=&#39;olive&#39;)
plt.title(&#34;提前预定时间对预订取消率的影响&#34;, fontsize=16)
plt.xlabel(&#34;提前预订时间&#34;, fontsize=16)
plt.ylabel(&#34;预订取消的概率&#34;, fontsize=16)
plt.show()
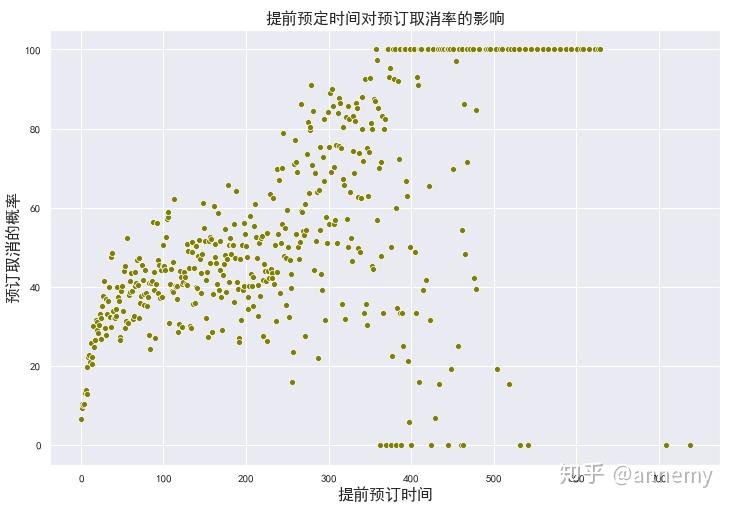
提前预订时间越长,预订取消率越高。酒店应当结合具体经营成本考虑是否限定提前预订的最长时间,以避免资源的占用。
#预定取消与保证金类型的关系
deposit_cancel_data = data_done.groupby(&#34;deposit_type&#34;)[&#34;is_canceled&#34;].describe()
plt.figure(figsize=(12, 8))
sns.barplot(x=deposit_cancel_data.index, y=deposit_cancel_data[&#34;mean&#34;] * 100,palette=&#34;Blues&#34;)
plt.title(&#34;Effect of deposit_type on cancelation&#34;, fontsize=16)
plt.xlabel(&#34;Deposit type&#34;, fontsize=16)
plt.ylabel(&#34;Cancelations [%]&#34;, fontsize=16)
plt.show()
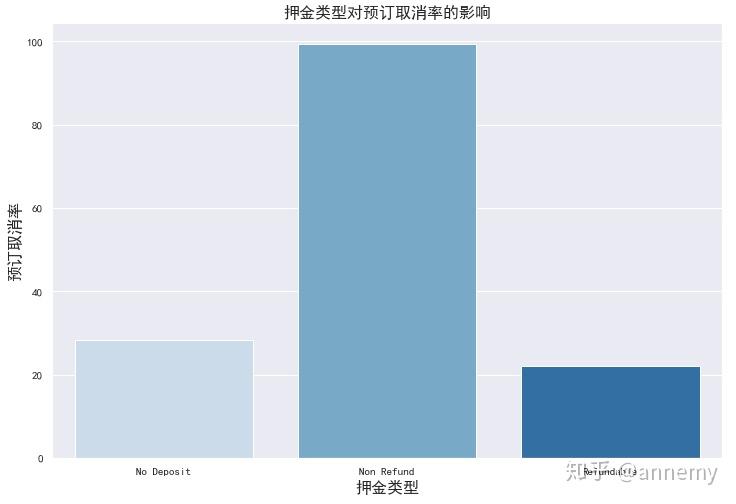
押金不退还的预订取消率在所有押金类型中最高,这种现象与观念中的消费者心理有些背离,再一步分析:
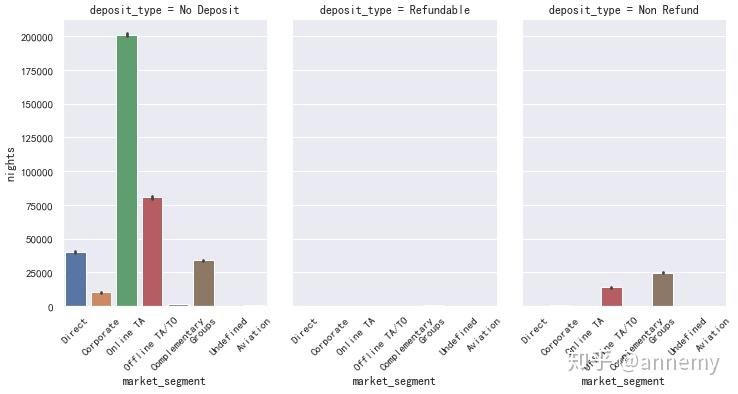
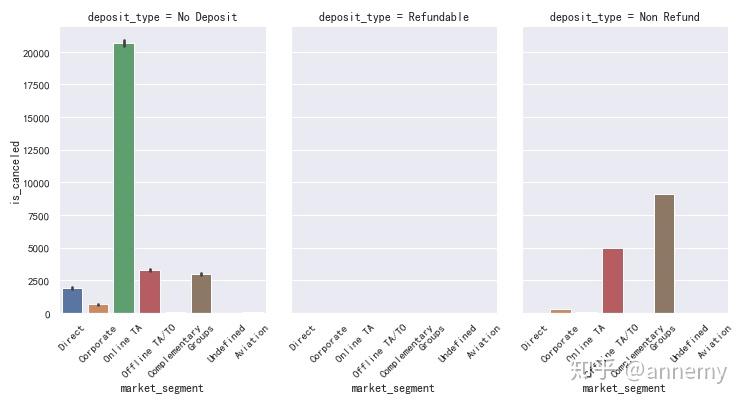
各个市场细分渠道中,线下旅行社代理预订以及团体预订的取消率最高,而在押金类型中,无押金的预订量主要集中在在线预订,而不退押金的预订量主要集中在线下旅行社代理预订以及团体预订,导致不退押金的预订取消率较高。酒店可以尝试设计问卷,对线下旅行社以及团体进行访问,探寻原因及解决方法。 |
|



 发表于 2023-3-24 17:18:18
发表于 2023-3-24 17:18:18